![]()
![]()
Chapter 3 - Network Summary Information and Statistics
This chapter describes summary statistics and information, which you view from the VINES Network Summary menu. This menu is the first one you see when you select one or more servers for monitoring. The chapter discusses the following topics:

VINES Network Summary menu and each statistic that you can view on it. How VINES servers manage memory. This information helps you to interpret the swapping average (Swavg) statistic. Note: The VINES Network Summary menu displays a list of VINES servers. This chapter explains the statistics on the menu that you can view for VINES servers.
The VINES Network Summary menu displays summary information and statistics for each server that you selected for monitoring. The menu displays the headings that describe each statistic, and the server name as the StreetTalkTM service knows it. A sample VINES Network Summary menu appears as follows.

You can display detailed configuration information and statistics for each displayed server by choosing one of the options listed in the top half of the menu. The chapters that follow describe these options in detail.
The sections that follow describe headings on the bottom half of the VINES Network Summary menu.
This heading displays the product version that each server on the menu is currently running. Servers are listed under server name.
Server load averages are exponential decaying averages that measure CPU activity on VINES servers.
VNSM counts the number of processes waiting for CPU time at each of these intervals:
Per minute Per 5-minute period Per 15-minute period
In calculating server load averages, a process is defined as a UNIX process. Examples of UNIX processes on servers include services that handle user activity or communications processes that route packets.
Although kernel (server operating system) interrupts and maintenance routines are also run by the CPU, they are not counted because they are not scheduled for CPU time in the same way that processes are.
If the CPU is always available to run the next process immediately, the load average values will be 0.0.
When the CPU cannot run a process immediately, the CPU scheduler places the process on a run queue. The scheduler also maintains a swap queue, where it places processes that are swapped out of memory, but are not yet completed. The load average statistics count all processes that are waiting to run by adding the totals of the swap queue and the run queue.
VNSM uses the following exponential decaying average formula to calculate load averages:
clavg = (llavg * weight) + (1 - weight) * ((lcp - llp)/interval)
The elements of this formula are as follows:
clavg - Load average for the current sampling interval. This is the average that VNSM currently displays.
llavg - Load average for the last sampling interval. This is the average that VNSM previously displayed.
weight - The weight is 0.1 for the 1-minute decay interval, 0.631 for the 5-minute decay interval, and 0.857 for the 15-minute decay interval.
lcp - The load in the current sampling interval. lcp is calculated as follows:
lcp = crque + csque
where crque is the average number of processes in the run queue during the current sampling interval and csque is the average number of processes in the swap queue during the current sampling interval. The average number of processes in the run queue is based on the time during the sampling interval that the CPU is running processes. By the same token, the average number of processes in the swap queue is based on the time during the sampling interval that the CPU is swapping processes.
llp - The load in the last sampling interval. llp is calculated as follows:
llp = lrque + lsque
where lrque is the average number of processes that were in the run queue during the last sampling interval, and lsque is the average number of processes that were in the swap queue during the last sampling interval. The average number of processes in the run queue is based on the time during the previous sampling interval that the CPU was running processes. By the same token, the average number of processes in the swap queue is based on the time during the previous sampling interval that the CPU was swapping processes.
interval - The sampling interval (60 seconds).
For a description of sampling interval and decay interval, see the section "Computed Statistics" in Chapter 2.
The load average statistics tell you the rate at which processes are being added to these queues. For example, a load average value of 1.0 means that processes are being placed on a queue at a rate of one process per second.
Note: The load averages can increase as more services are added to the server and as the server becomes more active. This happens because the server has to handle more requests and do more process switching.
The 1-minute load average should not exceed 1.0 on a regular basis. This value indicates a peak load. A peak load condition can result in application-level errors at the workstation, such as "File not found," or StreetTalk errors such as:
File volume Name@Group@Organization not available
These errors are caused by client programs not receiving responses within an extended period of time. A process will time out if the CPU cannot run it. However, other problems can also cause timeouts, such as a slow routing server or excessive messages (see the Mavg field, below). The theoretical maximum load is equal to the number of entries in the process table. See Chapter 14 for more information on the process table.
The 15-minute load average should not exceed 0.6 on a regular basis. This value indicates a steady state load that is large enough to slow performance at any workstation.
Avoiding Excessive Load Averages
Server load averages can be brought within acceptable limits by taking the following actions:
Limit the number of users of a service if the amount of user demand on the service is excessive. Delete or move services to other servers. View service statistics for this server to determine which services to move. See Chapter 7 for more information. If the Swavg value is greater than 0.01, reduce the amount of total file system cache available to services. Doing so provides more memory in which the services can run. Excessive process swapping also affects performance.
The Mavg value is a 1-minute exponential decaying average of the number of server messages sent and received per second.
Server messages are defined as either communications messages to other servers and workstations on the network, such as broadcasts, or internal messages between VINES services over the network or on the same server.
A high value indicates the presence of heavy message traffic, not necessarily heavy CPU activity. For example, a program that does swapping, such as a database application or a word processing application, can generate high message traffic but low CPU load averages.
Some services affect both types of averages. For example, a user sending mail to *@*@* causes the Intelligent Messaging mail service to perform calculations to determine who the recipients are and where they are located. This action results in a high CPU load average but a low message count. The message count increases as the service routes the message to other servers on the network, but it does so at a slower rate than the CPU load average.
Since the Mavg value provides information over the last 1 minute of activity, it is useful only for a load analysis of that period. It does not provide historical information.
VNSM uses the following exponential decaying average formula to calculate message averages:
cmavg = (lmavg * weight) + (1 - weight) * ((tcp - tlp)/interval)
The elements of this formula are as follows:
cmavg - Message average in the current sampling interval. This is the average that VNSM currently displays.
lmavg - Message average in the last sampling interval. This is the average that VNSM previously displayed.
weight - The weight is 0.1 (1-minute decay interval).
tcp - The total number of network messages and local messages sent and received in the current sampling interval. The tcp is calculated as follows:
tcp = ctotalout + ctotalin
where ctotalout is the total number of messages sent in the current sampling interval and ctotalin is the total number of messages received in the current sampling interval.
tlp - The total number of network messages and local messages sent and received in the last sampling interval. The tlp is calculated as follows:
tlp = ltotalin + ltotalout
where ltotalin is the total number of messages received in the last sampling interval and ltotalout is the total number of messages sent in the last sampling interval.
interval - The sampling interval (60 seconds).
For a description of sampling interval and decay interval, see the section "Computed Statistics" in Chapter 2.
For VINES servers, the Msgin (network messages received) and Msgout (network messages sent) values are the total number of network input/output messages processed since the last time any workstation or console running the VNSM program requested information from that server. If no workstation or server console in the network requests information from the VNSM program on the server for approximately 30 minutes, these values are set to zero. If one workstation or server console runs VNSM and asks for statistics on several servers, each of those servers starts counting Msgin and Msgout totals. Subsequent workstations that run the VNSM program and look at the same servers see the same values.
The following message types are included in the Msgin and Msgout counts:
Network message that is sent or received by a VINES service. Network layer packet that is sent or received by the VINES RouTing Update Protocol (RTP), the VINES Internet Control Protocol (ICP), or the VINES Address Resolution Protocol (ARP). These packets perform routing update and addressing functions in the network.
The Msgin and Msgout values are part of the basis for the Mavg value, discussed earlier (local messages that are sent or received are the other part). Use these values only to determine the relative workload across multiple servers. To do so, evaluate the rate at which the values are increasing for each server. For example, if the Msgin and Msgout values increase at approximately the same rate for several servers, then the message load on those servers is evenly balanced.
Msgin and Msgout have no upper limit, since they depend on how long the workstation has been running the VNSM program.
Reducing Message Load
You can reduce the message load on a given server by taking the following actions:
Limit the number of concurrent users. Move services (usually file services) that generate high message traffic to other servers. Reduce the amount of network traffic that the server routes. For example, you could cable your network so that traffic is routed through other servers.
The Drops value is the number of messages ignored by the VINES server since it was last booted. An example of an ignored message is one that a LAN card in the server accepted but could not process further, because of a lack of communications buffer space.
Some causes of exhausted buffer space are as follows:
Services are generating messages faster than the server can handle them. This condition can occur if many people do large file copies, document searches, or program loads at once. Noise on a LAN can make a LAN card generate continuous interrupts to the server. The server must attempt to process each interrupt as if it indicated a good packet coming off the network, even though most interrupts are mere noise. Use of communication buffer space is inefficient due to heavy activity on an interface that requires fragmentation and reassembly of messages. HDLC is an example of such an interface. Increasing the total amount of communication buffer space on the server can help remedy this problem. See Chapter 6 for more information on communication buffer space.
An unchanging drop value is acceptable. It indicates a peak loading condition that the server initially could not handle, but the load has since subsided. No data is lost because higher-level software protocols force retransmission of the ignored data.
Avoiding Excessive Drops
The number of drops are excessive if there are more than 200 drops per 100,000 messages sent and received. To calculate the number of messages sent and received, add the Msgin and Msgout counts.
If there are 200 or more drops per 100,000 messages, determine whether you have a network-level problem or a server loading problem, as follows:
Check the interface statistics for the server. If the interface statistics for a LAN connected to the server show high error counters, assume that the cause is a network-level problem involving faulty hardware. See Chapter 4 for more information on interface statistics. If the interface statistics are acceptable, but the server load and message averages are high consistently, assume that the cause is a server loading problem. Either reduce the number of concurrent users, increase communication buffer space or move services to another server. See Chapter 15 for more information on increasing communication buffer space.
Swavg stands for swapping average. When all the services that are currently active do not fit into RAM, the VINES server must swap services or parts of services between memory and disk, as needed.
If the server swaps at all (at a rate of 0.01 or more), system memory is over-used. If the server performs no swapping (0.0), system memory could still be over-used. Keep in mind that servers perform paging in addition to swapping. Even if Swavg is 0.0, a server could still be paging. See "How VINES Servers Manage Memory" later in this chapter for more information on paging and swapping.
Correlate swapping average with the operating system statistics, bswpi/s and bswpo/s. Swapping average is a good general indicator of swapping activity. Bswpi/s and bswpo/s provide more specific information on swapping than the swapping average statistic. See Chapter 14 for more information on bswpi/s and bswpo/s.
The swapping average is an exponential decaying average, which indicates the rate of swapping and not the number of swaps. It shows the sum of the number of data blocks that are moved to and from the disk's swap space over a 15-minute period. You should operate the server at a swap average of less than 0.01. Server performance degrades significantly at a higher average.
VNSM uses the following exponential decaying average formula to calculate swapping averages:
cswavg = (lswavg * weight) + (events * (1 - weight))
The elements of this formula are as follows:
cswavg - Swapping average in the current sampling interval. This is the average that VNSM currently displays.
lswavg - Swapping average in the last sampling interval. This is the average that VNSM previously displayed.
weight - The weight is 0.857 (15-minute decay interval).
events - This element factors in the total number of blocks swapped to and from disk during the current sampling interval and during the last sampling interval. events is calculated as follows:
(3 * T) * ((cswapin + cswapout) - (lswapin + lswapout))
T is equal to 60 seconds.
cswapin is the total number of blocks swapped into RAM in the current sampling interval.
cswapout is the total number of blocks swapped to disk in the current sampling interval.
lswapin is the total number of blocks swapped into RAM in the last sampling interval.
lswapout is the total number of blocks swapped to disk in the last sampling interval.
For a description of sampling interval and decay interval, see the section "Computed Statistics" in Chapter 2.
For servers with swap averages consistently over 0.01, performance might be improved if services with a heavy activity level are moved off disk 1. Moving services to another disk takes advantage of the overlapped seek capability, where the server can conduct overlapping operations to two or more disks simultaneously. To determine which services have a heavy activity level, see Chapter 7. To determine whether a disk is overloaded, see Chapter 9. To obtain information on available swap space on disk and available memory for processes to run in, see Chapter 14, "Operating System Information."
You can also take one or more of the following actions to reduce swapping:
Add more RAM to the server. Move services to another server. Stop or delete lightly used or unused services. Reduce the number of users of heavily used services. Reduce the amount of total file system cache in the server. For information, see Chapter 15.
If your server swaps, look at the disk usage statistics to see if one disk has a disproportionate share of activity.
To acquire an in-depth understanding of the Swavg statistic, it is necessary to understand how servers manage memory. The next section explains server memory management in detail.
How VINES Servers Manage Memory
Memory in a VINES server provides the resources that the server needs to perform its tasks. Memory is partitioned into the following areas:
Executable space. This area of memory provides the resources that executable code requires. The following elements share executable space:
- The kernel, which consists of UNIX, files (such as configuration files) that are loaded into memory, and internal processes that implement communication protocols such as VINES IP, IPC, and SPP.
- Drivers (for example, LAN drivers or protocol drivers such as TCP/IP and AppleTalk).
- Services.
Communication buffer. This area of memory is shared by the following elements:
- Messages that are formatted for reception or transmission.
- Overhead for transport layer protocol connections, such Sequence Packet Protocol (SPP), Transmission Control Protocol (TCP), and AppleTalk Session Protocol (ASP) connections.
- Sockets.
File system cache space. This area of memory provides a temporary holding area for frequently accessed files. This area of memory is used by file system cache, which file services use to perform file I/O operations.
Figure 3-2 shows the relationship between the areas of memory and the elements that share these areas.
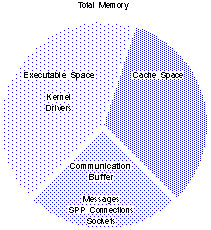
Enough memory must be available to meet the demands of the elements at a given time. Otherwise, performance problems result. When you analyze a server's memory requirements, remember that an increase in the memory required for one or more elements decreases the amount of memory available for others. For example, if you make more memory available for file system cache, you decrease the amount of memory available for services.
The kernel requires a fixed amount of memory, which is typically in the 1 MB to 1.5 MB range, depending on the server platform.
File system cache space is divided into temporary holding areas, called cache buffers, for recently accessed data from disk files. When a process such as a service asks the kernel to read or write data that resides in cache space, the kernel can complete the request quickly. The kernel does not have to read the data from its disk file or perform a complete write of the file to disk. This improves overall server performance.
When VINES is first installed, the cache space size is set to a default. The default value depends on the amount of memory in the server. See Chapter 15 for more information on the default cache space sizes for VINES.
You can configure the cache space size and the cache buffer size. Chapter 15 provides some guidelines and instructions for configuring cache space.
The communication buffer provides a temporary holding area for message traffic between the services running on a server and the physical media, such as a LAN or a serial line. Communication routines that implement the various VINES protocols use this buffer to format messages. When a server acts as a router, the buffer also provides a holding area for traffic that passes through the server.
Device drivers are programs that control input/output devices, such as LAN cards. Most device drivers do not require a lot of memory, and their memory requirements are fixed. For example, a typical Ethernet LAN card driver requires around 8 KB of memory.
The amount of memory that is not used by the kernel, communication buffer, cache space, or drivers supports services and internal system processes. Keep in mind that service activity can affect use of the communication buffer, sockets, and SPP connections. Remember that services require resources from the communication buffer to communicate with clients and other services.
Servers use a combination of paging and swapping to manage memory. Servers page when moderately loaded and swap when heavily loaded. Paging involves taking data that is not used very much out of 4 KB pages and moving it to disk, thereby making the pages available for data that is used more often. This allows part of the service to remain in memory. In order for paging to occur, a minimum amount of the service, called the minimum code space, must reside in RAM.
When not even the minimum code space fits in RAM, swapping occurs. Swapping involves moving the entire service, in 512-byte blocks, to an area of the disk called swap area.
Even moderate paging reduces system throughput and should be avoided. Swapping should be avoided under all circumstances. The Swavg statistic helps you determine the amount of paging and swapping your server can handle.
How the Kernel Allocates Memory to Services
To understand how the kernel allocates memory to services, it is important to understand how services are designed.
A service that has a single process can function as if it consisted of multiple processes. To do this, services use a special tasking system, called the VINES tasker, which divides each process into multiple tasks that consist of one or more procedures.
Services ask the kernel to allocate more memory to meet their needs as they create tasks. Each task requires a stack. Services also need to maintain more information in memory to keep track of user sessions, StreetTalk information, etc. The kernel always complies with these requests, and the services act and behave as if they are the sole owners of the memory. However, the kernel tricks services into thinking that the memory allocated to them is physical when in reality the memory that the kernel allocates is virtual. Note that a stack size is the amount of virtual memory that a task asks the kernel to supply. In most cases, the actual amount of memory that the task uses is a fraction of the stack size.
On 386TM servers and 486TM servers, if the memory requirements of the services exceeds the available memory, the kernel switches pages back and forth between the services as needed. Data in these pages is constantly moved to the disk. If the kernel cannot switch pages fast enough to keep up with service demand, services then compete for pages, causing a condition called thrashing. Thrashing results in severe performance degradation.
Thrashing can worsen to a point where the kernel must swap entire services to disk. This point is called the paging limit. When the server reaches its paging limit, serious performance degradation occurs. Symptoms of this degradation include extremely poor response time and sessions timing out due to insufficient resources.
![]()
![]()
![]()