![]()
![]()
Chapter 7 - Service Statistics
This chapter describes the statistics about services on servers that you can view through VNSM. A service is a process that runs under UNIX on a server. Services either provide network resources to users, such as file volumes, printers and 3270/SNA gateways, or perform network administrative and support functions, such as Server service, Security service, and StreetTalk service.
For more information on services, see Managing VINES Services.
To view service statistics, choose SHOW service statistics from the VINES Network Summary menu. The Service Statistics screen appears, as follows.
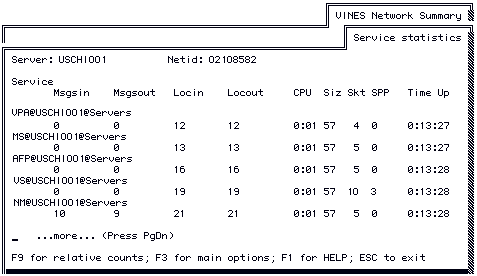
To return to the VINES Network Summary menu, press ESC.
In addition to the services that have been explicitly defined on the server, the following can also appear:
SS - Server service, which provides communication among processes on the server.
ST - StreetTalk service, which manages naming in a network.
VS - Security service, which manages network security.
SNM, NM, and VCS - Network and systems management services.
Nine fields of information appear for each service. The first four fields display the total number of messages sent and received, both locally (Locin and Locout) and over the network (Msgsin and Msgsout). The same internal process-to-process communications mechanism is used for both Msgsin/Msgsout messages and Locin/Locout messages. You can use the formula below to determine the total messages processed by a service:
Msgsin + Msgsout + Locin + Locout = Total
These fields can help you identify why a server is processing message traffic, and which services are responsible for large demands on the processor. If a server is overloaded or response is poor, you can use this display to choose one or more services to move to other servers.
The next four fields provide statistics on the amount of server CPU, virtual memory, and communication resources that each service consumes. These fields are only available from VINES 5.00, and VINES 5.50 and later servers. They fields fill with dashes when you press F9, indicating that relative counts do not apply to them.
The last field shows how long the service has been running. This field fills with dashes when you press F9, indicating that relative counts do not apply to it.
The sections that follow discuss the fields on the Service Statistics screen in detail.
Note: The last five fields of information on the screen may not appear for some servers. In this case, the product revision on those servers does not support the statistics.
Msgsin and Msgsout
Msgsin is total count of messages received over the network due to user activity since the service was last started. Msgsout is the total count of messages sent over the network due to user activity since the service was last started.
A network message is sent by or received by a service over the network using Remote Procedure Calls (RPCs) or a data stream, such as an SPP connection. The message is encapsulated by various protocol headers. A sample network message is shown in Figure 7-2.
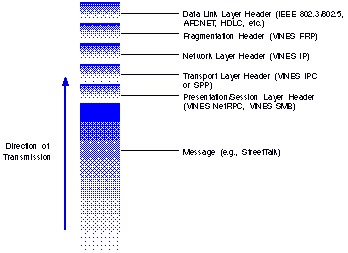
The exact format of the protocol headers depends on the protocols used to communicate. For more information on VINES protocols, see the VINES Protocol Definition.
Monitor the Msgsin and Msgsout statistics in conjunction with the communications buffer use and allocate failures statistics, which are described in Chapter 6. Make sure that sufficient communication buffers exist to handle network messages.
Do not compare the values for any services unless they were started at the same time. You can determine whether to compare values by viewing the Time Up statistic. This statistic shows how long each service has been running. The Time Up statistics is described later in this chapter.
In extreme cases, you may want to move user-created services that generate large amounts of network messages to another server. If services were started at the same time, you can determine which services are handling the highest percentage of message traffic by using this formula:
Service Msgsin + Service Msgsout x 100
--------------------------------------------------------------
Sum of Msgsin + Msgsout for all Services
Use this percentage and the Disk Usage statistics for the disk on which the service resides, to determine which services to move to another server.
In general, distribute heavily used file services across all the disks in a multiple-disk server. This approach optimizes disk seek performance because services on separate disks can be accessed simultaneously.
If other VNSM statistics indicate that your server is overloaded, move services to a server that can handle the load. When you move services, follow these two rules:

If the other server is on the same physical LAN as the workstations that will use it, move the service with the highest message traffic percentage. With this method, you off-load the current server without introducing any routing overhead. If the other server is on a backbone LAN, you should move several infrequently used services. This strategy allows you to maintain maximum performance of your heavily used service. In addition, you replace the service load of the moved services with a routing load that is usually smaller.
Locin and Locout
Locin is the total count of messages received locally due to server activity since the service was last started. Locout is the total count of messages sent locally due to server activity since the service was last started.
In the event of a high Locin/Locout count for a service, check the server logs to see if the service was trying to bring itself up.
Except for the Server service, StreetTalk service, and Intelligent Messaging mail service, services that have high values for Locin and Locout need some corrective action. Large Locin and Locout values for these services indicate that they are stopping and starting frequently. As a general rule, if the Locin and Locout values are equal to or greater than the Msgsin and Msgsout values, the service is failing.
CPU
The amount of current CPU use, in minutes and seconds, that the service is generating. CPU use is displayed in mm:ss format, where m is minutes and ss is seconds.
The amount of virtual memory, in 4 KB pages, that is allocated to the service. Multiply this figure by 4 to determine the total amount of virtual memory, in kilobytes, that is allocated to the service.
The amount of real memory (that is, RAM) that a service uses is a percentage of the amount of virtual memory that is allocated to it. If you add the Siz values of all the services, you will notice that the total greatly exceeds the amount of executable space (RAM) that is available to services. The Freemem statistic, which is described in Chapter 14, tells you the total amount of executable space that is available to services.
Do not use the Siz statistic to determine the exact amount of real memory that a service is using. Rather, use the statistic to determine which services are the largest consumers of memory.
Use this statistic in conjunction with the Swavg statistic on the VINES Network Summary menu, the Freemem statistic on the OS Information screen, and the Time Up statistic on the Service Statistics screen.
The Swavg statistic tells you when the memory requirements of all the elements that use memory - the kernel, services, file system cache, communication's buffer, drivers and internal system processes - exceed the amount of available physical memory in the server. See Chapter 3 for a description of the Swavg statistic.
The Time Up statistic tells you how long the service has been running. This statistic is useful when interpreting the Siz statistic because a service's memory use tends to increase the longer it is left running. The Time Up statistic is described later in this chapter.
After a service starts, the amount of virtual memory that is allocated to a service varies, depending on the service. In some cases, a service's memory requirements increase after it starts. A service starts in the following situations:
The server is rebooted. Services are restarted from the Operator Menu of the server console. The service is started through OPERATE or MSERVICE.
The factors that influence this increase are described in the section, "Factors That Influence Service Memory Use" at the end of this chapter.
The number of sockets that the service is currently consuming.
All services use sockets for network communications. If the total number of sockets that are consumed by services approaches the total number of sockets configured for the server, increase the number of sockets. See Chapter 15 for information on increasing sockets.
The Communication Resources Usage screen displays the total number of sockets currently in use and the total number of configured sockets for the server. See Chapter 6 for more information on displaying these statistics.
The number of Sequenced Packet Protocol (SPP) connections that the service is currently consuming. Some (not all) services use SPP to communicate with their respective clients. This field always displays 0 for the services that do not use SPP to communicate.
If the total number of SPP connections that are consumed by services approaches the total number of SPP connections configured for the server, increase the number of SPP connections. See Chapter 15 for information on increasing SPP connections.
The Protocol Statistics screen for SPP in VNSM displays the total number of SPP connections currently in use and the total number of configured SPP connections for the server. See Chapter 10 for more information on displaying these statistics.
This field shows, in day:hour:minute format, the amount of time that the service has been running.
Factors That Influence Service Memory Use
The amount of memory that services require after they start and the factors that influence memory use depend on the specific service. In general, the following factors influence service memory use:
The number of users of the service. As the number of users of a service increases, the amount of memory that the service uses tends to increase as well. Use the LOOK at service users function of MSERVICE to monitor the number of service users. For the StreetTalk and Security services, the number of groups and users maintained on the server.
Using the Siz statistic, monitor service memory use over time to determine which services are the largest consumers of memory. Keep in mind that the Siz statistic shows the amount of virtual memory that is allocated to a service and that the amount of real memory that the service uses is a percentage of its allocated virtual memory. Pay close attention to the following services:
StreetTalk service Security service Intelligent Messaging mail service Print service SMTP service STDA service AFP service Asynchronous Terminal Emulation service
If the Swavg and Freemem statistics indicate that the server does not have enough memory for services to run in, you can take one of the following actions:
Modify the size of cache space. This frees up memory for services to run in. See Chapter 15 for information on modifying the cache space. Move services to servers that have sufficient memory capacity. Stop unused or lightly used services. Shut down and restart server software if swapping average remains above .01 for a long period of time. Move large groups to other servers that have sufficient memory capacity or split up large groups into smaller groups and distribute them among several servers. Reduce the number of service users as long as alternative services that can handle additional users are available.
If you reduce cache space to provide more memory for services, try not to let your cache hit ratio go below 85 percent. Keep in mind that a low cache hit ratio is preferable to a lot of paging or swapping. See Chapter 8 for a description of the cache hit ratio statistic. See Chapter 15 for information on configuring cache space.
If you move services or groups to another server, make sure the other server has sufficient memory capacity to handle the additional workload. Consider reducing the cache space size on the other server, if possible. When you move the service to the other server, monitor the Swavg statistic to make sure that paging or swapping does not increase significantly.
In the case of heavily used services, consider telling users to switch to alternative services if available. For example, if you think that an Intelligent MessagingTM mail service on an overloaded server has too many users, ask them to use another mail service if one is available.
![]()
![]()
![]()